Dans une expression mathématique comme
(2+2+2)×(3+4)
les parenthèses servent à indiquer quelles sous-expressions doivent
être calculées en premier (la convention, en leur absence, étant qu'on
évalue les multiplications avant les additions, si bien que 2+2+2×3+4
sans parenthèses se comprend comme 2+2+(2×3)+4). Mais il existe
d'autres manières possibles d'indiquer l'ordre des opérations sans
utiliser de parenthèses — ou en tout cas pas sous cette forme. Une
possibilité consisterait à utiliser la notation préfixe (où
le symbole d'une opération binaire précède les deux quantités sur
lesquelles elles s'applique, ce qui donne dans ce
cas : × + + 2 2 2 + 3 4
) ou
bien postfixe (où l'opération binaire suit les deux quantités
sur lesquelles elle s'applique, donc 2
2 + 2 + 3 4 + ×
comme on le taperait sur une calculatrice à
notation polonaise inversée), mais ces conventions sont extrêmement
peu lisibles pour un humain.
Une autre façon de noter les choses, qui me semble assez intéressante ou en tout cas instructive, même si elle n'a jamais vraiment été utilisée en-dehors de la logique, consiste à utiliser les points comme parenthèses, que je veux présenter et discuter un peu. Sur mon exemple, cette notation donnerait :
2+2+2.×.3+4
avec des points autour du symbole de multiplication pour marquer qu'il doit être effectué après les additions. (On va supposer que le point n'est pas utilisé comme séparateur décimal, ou qu'il y a quelque magie typographique qui évite l'ambiguïté : ni ici ni ailleurs dans cette entrée il n'y a de nombres fractionnaires.)
La manière dont on lit une telle expression est la suivante : on commence par la séparer aux endroits où se trouve des points, on évalue tous les morceaux qui ont un sens en tant qu'expression (en l'occurrence, 2+2+2 et 3+4), puis on réattache les morceaux remplacés par leur valeur (ce qui donne 6×7).
Lorsqu'il y a plusieurs niveaux d'imbrications, on utilise des groupes formés d'un nombre de points croissant pour séparer les niveaux : la règle est alors qu'on commence par regrouper les morceaux séparés par un seul point, puis par un groupe de deux, puis de trois, et ainsi de suite. (Ainsi, un groupe d'un plus grand nombre de points correspond à un niveau de parenthésage plus « extérieur ».) Par exemple,
(14/(1+1))×(6+7)×(30−(6+5))
peut se réécrire dans la notation « ponctuée » comme
14/.1+1:×.6+7.×:30−.6+5
et pour l'évaluer, on commence par calculer les morceaux séparés par des points qui ont un sens tout seuls (1+1, 6+7 et 6+5), puis on regroupe les morceaux séparés par de simples points (14/.1+1 soit 14/2, et 30−.6+5 soit 30−11), et enfin on regroupe les morceaux séparés par deux points. Pour plus de symétrie quant au niveau d'opération × dans le facteur central, on peut préférer écrire
14/.1+1:×:6+7:×:30−.6+5
ce qui est peut-être plus lisible, surtout si on reflète le nombre de points dans l'espacement de la formule :
14/.1+1 :×: 6+7 :×: 30−.6+5
On peut bien sûr utiliser des symboles pour les groupes de deux,
trois, quatre points et ainsi de suite : si je récupère des symboles
Unicode pas vraiment fait pour,
l'expression 6−(5−(4−(3−(2−1))))
peut se ponctuer
en 6−∷5−∴4−:3−.2−1
, mais généralement on se contente de mettre
plusieurs caractères ‘.’ ou ‘:’ d'affilée pour représenter un groupe,
comme 6−::5−:.4−:3−.2−1
(il faut traiter ces deux écritures
comme parfaitement synonymes).
Les points servent donc à la fois de parenthèses ouvrantes et
fermantes : il n'y a en fait pas d'ambiguïté car la directionalité est
indiquée par la position par rapport aux symboles d'opérations (si je
vois 20−.1+1
, cela ne peut signifier que 20−(1+1)
car (20−)1+1
n'a pas de sens) ; plus exactement, chaque groupe
de points doit être adjacent à un symbole d'opération (sauf si on omet
la multiplication, cf. ci-dessous), et correspond à une parenthèse
soit ouvrante soit fermante selon qu'il est immédiatement après ou
avant l'opération. Et la parenthèse court jusqu'au prochain groupe de
points (vers la droite ou vers la gauche, selon le cas évoqué) dont le
nombre de points est supérieur ou égal à celui considéré, ou à
l'extrémité de l'expression (où se sous-entend un nombre infini de
points, si on veut ; ainsi, sur mon premier exemple, on
écrit 2+2+2.×.3+4
et non .2+2+2.×.3+4.
).
Pour ceux qui veulent des règles plus formelles,
je propose les suivantes. En écriture, si on a un arbre d'analyse
formé d'opérations possiblement associatives,
disons x1⋆x2⋆…⋆xk
(pour une certaine opération ici notée ⋆, et avec k=2 si
l'opération ⋆ n'est pas supposée avoir d'association par défaut), pour
la transformer en « expression ponctuée », on écrit de façon récursive
chacun des
sous-arbres x1,x2,…,xk
comme expression ponctuée, et on concatène ces écritures en plaçant à
gauche de chaque symbole ⋆ un groupe de points dont le nombre est
strictement supérieur au nombre de points de n'importe quel groupe
apparaissant dans l'écriture de la sous-expression gauche (si celle-ci
est un atome = une feuille de l'arbre, c'est-à-dire un nombre ou une
variable, on peut ne mettre aucun point) ; et de même à droite. Il
est admissible de mettre plus de points que nécessaire, par exemple si
on veut mettre le même nombre à gauche et à droite de chaque ⋆
intervenant à un niveau donné. On peut, bien sûr, avoir des règles
supplémentaires lorsqu'on suppose une certaine priorité des opérations
(par exemple, (3×2)+1
peut être noté 3×2+1
si on admet
que la multiplication est prioritaire sur l'addition ; toutefois, ceci
ne s'applique essentiellement qu'au niveau le plus
bas : (3×(1+1))+1
devra certainement être
noté 3×.1+1:+1
, parce qu'on ne gagnerait rien que de la
confusion à le noter 3×.1+1.+1
). • Inversement, pour décoder
une telle expression, on va, pour n allant de 0 au nombre
maximum de points dans un groupe, remplacer chaque expression
maximale de la
forme x1⋆x2⋆…⋆xk
avec les xi des sous-arbres déjà
constitués (ou des atomes), en ignorant les groupes de ≤n
points pouvant intervenir à gauche ou à droite de l'opération ⋆, par
un sous-arbre (ou un bloc parenthésé, si on préfère).
Ce système de notations ne recouvre pas tous les cas possibles
d'usage des parenthèses. Disons qu'il nécessite plus ou moins qu'il y
ait des symboles d'opérations dans l'histoire : si on a affaire à un
contexte mathématique dans lequel on donne un sens différent aux
notations u(v)
et (u)v
(ce qui, honnêtement, ressemble à
une très mauvaise idée), ou à u
et (u)
(même remarque), alors on ne peut pas
utiliser des points à la place des parenthèses.
Néanmoins, il marche dans des situations un peu plus générales que
ce que j'ai présenté ci-dessus. Par exemple, il continue de
fonctionner même si on décide de ne pas écrire le symbole × de
multiplication : notamment, si dans la version parenthésée, au lieu
de (14/(1+1))×(6+7)×(30−(6+5))
je décide
d'écrire (14/(1+1))(6+7)(30−(6+5))
, alors de même dans la
version ponctuée, au lieu de 14/.1+1:×.6+7.×:30−.6+5
j'écris 14/.1+1:6+7:30−.6+5
et il n'y a pas d'ambiguïté dans le
fait que quand un groupe de points apparaît directement entre deux
atomes (nombres ou variables), il représente une multiplication (et
comme 6.7
représente 6×7
, de même 2+2+2.3+4
représente (2+2+2)×(3+4)
; tandis que 2+2+(2×3)+4
s'écrira 2+2+:2.3:+4
ou même, un peu
audacieusement, 2.+.2.+.2.3.+.4
si on décide que la
multiplication est prioritaire sur l'addition). Ceci fonctionne
encore même si on suppose que la multiplication omise n'est pas
associative : on distingue
bien u(vw)
de (uv)w
comme u.vw
et uv.w
respectivement.
Par rapport aux règles formelles que j'ai
proposées ci-dessus, l'omission du symbole de multiplication se traite
ainsi lors de l'écriture : (a) on écrit toujours au moins un point
pour la multiplication quand elle est entre deux chiffres, et (b) au
lieu de mettre un groupe de points à gauche et à droite du symbole ⋆
(qui doit être omis), on en met un seul, avec un nombre de points
commun, supérieur à celui de tout groupe intervenant dans
n'importe quelle sous-expression parmi
les x1,x2,…,xk
(avec cette
règle, 2(x+y)(t⋆(u+v))
s'écrit 2:x+y:t⋆.u+v
plutôt
que 2.x+y:t⋆.u+v
si on veut vraiment placer les trois facteurs
2, x+y
et t⋆(u+v) au même niveau).
Il n'y a pas non plus de problème avec les opérations unaires,
qu'elles soient écrites de façon préfixe ou postfixe. Il y a,
cependant, un problème si on a une opération qui peut être aussi bien
unaire que binaire et que le symbole de multiplication est
omis : c'est le cas avec le signe moins si on veut pouvoir
écrire (2/3)(−3)
(qui vaudrait −2 par multiplication implicite)
et le distinguer de (2/3)−3
(qui vaut −7/3), les deux
étant a priori ponctués comme 2/3.−3
; on peut résoudre
ce problème de différentes façons, par exemple en imposant que pour
les opérations binaires qui peuvent aussi être unaires, le nombre de
points à gauche et à droite soit égal quand elles fonctionnent comme
opérations binaires (donc (2/3)−3
se ponctuerait
comme 2/3.−.3
, qui se lit sans ambiguïté), et/ou que le signe
de multiplication ne peut pas être omis devant une opération unaire
(donc (2/3)(−3)
devrait s'écrire 2/3.×.−3
).
Il me semble par ailleurs qu'il n'y a pas de
problème particulier avec une opération ternaire (par exemple si je
décide que t?u!v
signifie si t=0 alors v et
sinon u
— je change légèrement la notation du C parce
que les deux points sont pris par le sujet de cette entrée — alors il
n'y a pas de problème à écrire de façon ponctuée des expressions
contenant cette expression imbriquée en elle-même de façon
arbitraire). Ceci étant, je n'ai pas forcément pensé à toutes les
bizarreries des notations mathématiques, peut-être qu'il y a des cas
où le système de points ne fonctionnera pas alors que les parenthèses
fonctionnent (outre ceux que j'ai déjà mentionnés).
Il faut que j'en profite pour signaler qu'il y a
toutes sortes de petites variations possibles dans le système, j'en ai
déjà implicitement signalé quelques unes. Je mentionne notamment la
suivante, qui est plus économique dans le nombre de points utilisés,
au détriment de la lisibilité de l'ensemble, et qui me semble plutôt
une mauvaise idée. Plus haut j'ai signalé
que 6−(5−(4−(3−(2−1))))
s'écrit 6−::5−:.4−:3−.2−1
(et
c'est ce qui résulte des règles formelles que j'ai proposées), mais on
peut aussi imaginer l'écrire simplement come 6−.5−.4−.3−.2−1
ce
qui est après tout inambigu vu que chaque ‘.’ suivant immédiatement un
symbole d'opération doit représenter une parenthèse ouvrante. (La
modification des règles formelles que j'ai proposées doit être quelque
chose comme ceci. En écriture, on place à gauche de chaque symbole ⋆
un groupe de points dont le nombre est immédiatement strictement
supérieur au plus grand nombre de points de n'importe quel groupe qui
apparaît, dans l'écriture de la sous-expression gauche, immédiatement
à droite d'un symbole d'opération — ou comme symbole de
multiplication omis — en ignorant donc les groupes de points qui
apparaissent immédiatement à gauche d'un symbole d'opération ; et
symétriquement pour la droite. Et en lecture, pour chaque
niveau n de points, on doit grosso modo répéter tant que
possible la recherche d'une
expression x1⋆x2⋆…⋆xk
avec les xi des sous-arbres déjà
constitués, la remplacer par un sous-arbre, et retirer les éventuels
groupes de n points — mais pas plus — qui seraient
adjacents à l'expression.)
Comme je l'ai dit plus haut, je crois que les points comme parenthèses n'ont été véritablement employés que dans des textes de logique (et uniquement entre les connecteurs logiques, pas dans les expressions arithmétiques comme sur les exemples que j'ai pris), même s'il n'y a pas de raison de la lier à ce contexte précis. Je ne sais pas exactement qui a inventé cette notation : peut-être Peano dans ses Arithmetices principia: nova methodo ; mais je sais surtout qu'elle est utilisée dans les Principia Mathematica de Russell et Whitehead dont elle contribue à la réputation d'illisibilité même si je crois que c'est loin d'être ce qui les rend le plus difficile (on pourra jeter un coup d'œil à la page des Principia que j'ai déjà évoquée sur ce blog, et utiliser cette page pour quelques indications sur comment décoder tout ça). J'ai d'ailleurs l'impression que les philosophes qui s'intéressent à la logique mathématique ont, plus que les logiciens vraiment matheux, tendance à utiliser des notations vieillotes (il y a peut-être une raison sociologique à creuser), et en particulier ces points-comme-parenthèses. Il y a aussi l'épouvantable symbole ‘⊃’ utilisé à la place de ‘⇒’ pour l'implication, que la grande majorité des matheux ont abandonné il y a belle lurette, et que des philosophes s'obstinent, Apollon sait pourquoi, à utiliser.
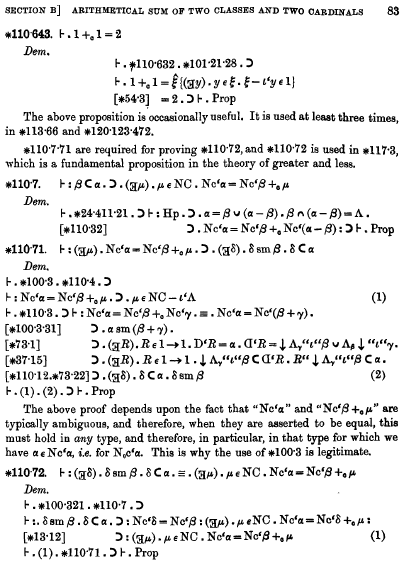{kind=link}
Mais l'autre question à se poser, bien sûr, c'est : ce système de
notation avec des points à la place des parenthèses a-t-il des
avantages ? Je sais qu'a priori il semble plus compliqué que
les parenthèses. Peut-être l'est-il intrinsèquement, mais je crois
que c'est essentiellement une question d'habitude (c'est difficile
d'être sûr vu que je n'en ai moi-même guère la pratique). Je vois
trois principaux arguments qu'on peut avancer pour défendre le système
de points : (1) il est légèrement plus compact (quand on discute une
opération non associative, il est plus léger
d'écrire uv.w
que (uv)w
, par exemple),
(2) on repère plus rapidement le niveau d'imbrication des choses (qui
n'a jamais peiné, dans une expression parenthésée, à retrouver où
chaque parenthèse se ferme ?), et (3) il est, finalement, relativement
analogue à la ponctuation d'un texte en langage naturel (où,
grossièrement parlant, on regroupe d'abord les mots non séparés par
une ponctuation, puis les groupes séparés par des virgules, puis ceux
séparés par des points-virgules, et enfin ceux séparés par des
points), rendu plus logique. Le principal inconvénient que je lui
vois, c'est que si on veut remplacer, dans une expression, une valeur
par une autre expression, on va possiblement devoir incrémenter le
nombre de points partout dans l'expression, alors que les parenthèses
assurent que tout se passe forcément bien.
Bien entendu, je ne propose pas de changer une notation mathématique bien établie (les parenthèses sont quand même pratiques, finalement), mais il peut être intéressant de se rappeler qu'il y a, ou qu'il y avait a priori, d'autres notations possibles et pas forcément idiotes. Se le rappeler peut aider à mieux comprendre l'analyse syntaxique, à la fois des expressions mathématiques et des phrases ponctuées en langage naturel (cf. mon point (3) ci-dessus) ; et cela peut aussi suggérer comment faciliter la lecture d'une expression mathématique par des enrichissements typographiques (typiquement : mettre à chaque endroit possible un espacement proportionnel au nombre de points qu'on aurait dans la notation avec les points comme parenthèses).