Je me suis acheté
un Nexus 5.
Principalement parce que j'en avais marre de mon ancien téléphone
(un Nexus 4) dont
le capteur de proximité merdait, ce
qui le rendait très pénible à utiliser, mais aussi à cause
d'un bug qui rend Google ridicule,
surtout que deux mois plus tard il n'a toujours pas été corrigé (et
toutes les façons de le contourner que j'ai essayées se sont avérées
merdiques) — bizarrement, il se trouve que ce bug affecte les Nexus
(Nexi ?) 4 et 6 mais pas le 5, ce qui est d'autant plus mystérieux que
ce n'est certainement pas un problème matériel. Mais la raison
secondaire de l'avoir acheté maintenant est que le Nexus 5 ne sera pas
disponible indéfiniment ; le Nexus 6 ne me convient pas du tout parce
qu'outre le bug sus-mentionné il est vraiment trop grand pour mes
poches (je ne comprends décidément pas du tout pourquoi les gens
aiment les phablets
) ; et il y a une chose que j'ai apprise en
achetant des choses en ligne, c'est qu'il ne faut jamais supposer
qu'un produit disponible un jour le sera encore dans un mois.
D'ailleurs, j'ai vu juste puisque, même pas une semaine plus tard, le
Nexus 5 n'a plus l'air vendu par Google.
Pour autant, je ne vais pas spécialement en parler, puisque je n'ai
pas rencontré de problème particulier, et le but de ce blog est quand
même avant tout de déverser mes râleries. À la place, je vais donc
parler d'Android en général, et de pourquoi j'en suis mécontent, pas
pour une raison logicielle ou matérielle particulière, mais pour,
disons, l'ambiance générale. Qui, il faut le dire, pue, au moins
quand on est habitué au monde Unix/Linux.
⁂
Au début, quand j'ai entendu parler d'Android, je me suis dit,
chouette, enfin un système qui va apporter un peu d'ouverture dans le
monde des mobiles où tout est verrouillé : enfin, on va pouvoir
décider un peu ce qui se passe sur son téléphone, changer des choses,
le « bidouiller » (le hacker, au sens
qu'avait
ce mot avant que la presse le tranforme en quelque chose de
négatif), bref, en être vraiment propriétaire. Las ! Android est
tombé bien loin de ces espérances.
Alors certes, le cœur du système est libre / Open Source. Du
moins, il faut le dire vite, parce qu'il y a plein de restrictions à
ça. Primo, ce qui est libre, c'est uniquement le système
avec un ensemble minimal d'applications : en fait, la grande majorité
des systèmes Android autres que les versions chinoises à deux balles
tournent avec, en plus, les Google Apps, qui,
elles, ne sont pas libres du tout (et le bug dont
je me plaignais est dans
les Google Apps, ce qui fait que je ne peux pas,
même ne principe, le corriger). Il y a des choses dans
les Google Apps dont je comprends plus ou moins
qu'elles ne soient pas libres (Google Maps, par exemple), il y en a
aussi qui font plus ou moins doublons avec des applications libres
d'Android
(voir cet
article d'Ars Technica pour un exposé de la situation), mais le
truc est surtout en train de se transformer en une énorme moussaka qui
contrôle totalement le téléphone au-dessus d'Android
(les Google Play Services), et le problème est
que non seulement c'est propriétaire, mais en plus il faut soit tout
accepter en bloc, soit tout rejeter — d'où la gravité du bug que j'ai
rencontré, et qui ne pouvait se résoudre qu'en coupant, de fait, tous
les services Google.
Secundo, la version libre officielle d'Android
(AOSP, pour Android Open Source
Project
), elle ne tourne que sur un tout petit ensemble de
téléphones, peut-être même aucun. Sans même parler des pilotes
propriétaires (comme le firmware radio, et de façon plus gênante, les
pilotes graphiques), la plupart des téléphones d'Android sur le
marché, en gros tout ce qui n'est pas un Nexus de Google (e.g., le
Samsung Galaxy Nimportelequel), vient avec une version d'Android
lourdement modifiée par le vendeur, et vous pouvez toujours rêver pour
avoir les sources de ce truc-là. Bon, il existe bien une version
dérivée d'Android, libre (aux pilotes et à quelques bricoles près),
qui tourne sur pas mal de téléphones, et c'est celle que
j'utilise, CyanogenMod, et
différentes versions sous-dérivées de celle-ci, mais ce n'est déjà pas
pareil que de dire qu'on a des systèmes libres sur la plupart des
téléphones du marché : ce n'est tout simplement pas le cas.
D'ailleurs, CyanogenMod est devenu un projet commercial, et je suis
persuadé qu'il ne va pas rester libre très longtemps. On voit plein
de petits signes montrant qu'il est de plus en plus fermé. (J'ai
aussi plein de reproches pratiques à leur faire, comme le
fait que leur système de nommage des versions est incompréhensible et
qu'ils n'arrivent jamais à produire une version stable de
quoi que ce soit, mais c'est un autre sujet.)
Tertio, quand bien même vous trouvez une version libre
d'Android qui tourne sur votre téléphone, si vous espérez que parce
que c'est libre vous allez facilement pouvoir faire des changements
dessus, détrompez-vous. Recompiler un Android est très, très, très
(très) difficile. Essentiellement, il faut une machine
dédiée à ça (éventuellement une machine virtuelle, certes), avec
exactement la bonne version d'Ubuntu, exactement la bonne version de
Java, exactement la bonne version des différents outils. Plein de
gigas d'espace disque (vraiment plein). Plein de mémoire. Plein de
temps. Et plein de bande passante réseau. Le problème principal,
c'est qu'Android n'est pas du tout conçu pour qu'on puisse bidouiller
avec (je cherche un équivalent français du
mot tinkering
) : on compile tout en bloc.
Recompiler une unique application système après l'avoir un petit peu
modifiée n'est pas du tout prévu ou supporté. (Par exemple,
j'avais fini par
trouver comment recompiler l'application clavier standard
pour la modifier et y mettre
notamment mon propre dictionnaire et quelques caractères Unicode
supplémentaires : j'en ai énormément bavé pour y arriver. Et je n'ai
jamais trouvé le courage d'en faire autant pour l'application
téléphonie pour contourner le problème du capteur de proximité cassé
sur mon Nexus 4.)
Mais il y a un problème plus fondamental : l'écosystème
Android est extrêmement hostile au logiciel libre. Voyez le
Google Play Store : il n'y a aucune indication de quelles applications
dessus sont libres / Open Source. Pire, il n'y a aucun moyen
standardisé pour un développeur Android de mettre une information
indiquant qu'une application est libre (il peut juste l'étiqueter
gratuite, ce qui n'est pas du tout pareil), ou pour indiquer où sont
les sources, ou quelle est la licence. Google n'offre même pas un
réglage caché pour développeurs ou enthousiastes du libre pour
dire je voudrais voir en priorité, ou exclusivement, des
applications libres
. Il y a bien
un marché
alternatif, F-Droid, pour ça, mais comme il est
alternatif, il n'a aucune publicité de la part de Google, du coup il
est très confidentiel, et il n'y a quasiment rien d'intéressant
dessus. Et de fait, il y a très peu d'applications libres pour
Android. Et les rares qui le sont ont même tendance à cesser de
l'être au bout d'un certain temps, quand le développeur se rend compte
que, tient, il pourrait peut-être monétariser le succès de son
application (ou pour je ne sais quelle autre raison) : j'en ai vu
plein, comme ça, qui étaient annoncées libres au début, et qui au bout
de quelques versions ne l'étaient plus (exemple au pif : l'application
d'écran de démarrage ADW Launcher,
qui eut été
libre et qui ne l'est plus du tout).
Cette atmosphère est très surprenante quand on vient du monde des
Unix libres, où on peut à peu près tout faire avec des programmes
libres (preuve qu'il y a bien des gens prêts à en écrire !). Sous
Android, quasiment toutes les applications vous laissent le choix
entre une version gratuite, lourdement limitée et/ou très
généreusement décorée de bandeaux publicitaires, et une version
payante. La mentalité de petits connards des programmeurs qui croient
opportun de demander paiement pour une petite merde qu'ils ont écrite
alors qu'à côté, dans le monde du logiciel libre pour PC
de bureau, il y a des gens qui écrivent des compilateurs C, des suites
bureautiques, des navigateurs Web, etc., et qui ne mettent pas de pub
dedans ni ne gardent leur code secret, me laisse sans voix.
(J'imagine un monde où gcc proposerait le choix entre une
version payante et une version gratuite, cette dernière refusant de
compiler un programme de plus de 2000 lignes et affichant au milieu
des messages de compilation des messages publicitaires vous informant
qu'il y a sans doute des célibataires dans votre région.) Et avant
que quelqu'un me sorte l'argument débile si tu n'es pas content de
ces programmes, tu n'as qu'à ne pas les utiliser
: ce n'est pas si
simple, parce qu'en étant le petit connard qui développe une petite
merde pour Android dont on ne donne pas les sources, on met un frein
psychologique au développement d'un logiciel libre remplissant la même
fonction.
(Et je pense que c'est vraiment un problème psychologique lié à la
« décision par défaut ». Si Google poussait pour que la décision
par défaut quand on écrit une application Android, soit qu'elle
soit libre, je suis persuadé que l'immense majorité des développeurs
ne se comporteraient pas comme ça comme des connards. I.e., la
différence entre Android et les Unix libres n'est pas tellement, à mon
avis, dans l'origine des développeurs, que dans le fait que dans un
cas publier le code source est considéré comme normal et dans
l'autre cas ça ne l'est pas. Pour une explication du genre de
phénomènes qui me fait penser ça,
voyez cet
exposé à TED de Dan Ariely, et ce qu'il dit sur
le don d'organes dans différents pays.)
Et le problème est d'autant plus aigu que la réponse à n'importe
quel problème sous Android est toujours There's An
App For That
: là où la bonne réponse à un problème dans Android,
si le système était véritablement ouvert, devrait être
quelque chose commme commentez la ligne 66 du
fichier server/InterfaceController.cpp dans le
dépôt platform/system/netd et recompilez votre
système
, la réponse est en fait installez MyNetworkControlApp
sur le Google Play Store et cliquez
sur disable IPv6 privacy
. Ce
qui est peut-être plus pratique pour le neuneu moyen, mais pour ma
part je n'ai aucune envie d'installer la petite merde
MyNetworkControlApp pour réparer les problèmes de mon téléphone, et
surtout pas de lui donner des droits exorbitants sans avoir vu le
code, ou au moins, sans avoir eu la possibilité en principe de voir ce
code.
Même si on met de côté le problème du code libre ou non, le système
Android n'est généralement pas favorable à la « bidouille » telle
qu'un unixien va avoir tendance à la comprendre et à la pratiquer.
Ceci se reflète par exemple dans le fait que peu de choses peuvent se
faire en ligne de commande (on peut réussir à se connecter à un shell
sur un téléphone Android, mais le plus souvent on ne peut pas y faire
grand-chose). Entre autres parce que les interfaces internes
d'Android (tout ce qui n'est pas utilisé par un programme final en
Java) est mal documenté ou pas documenté du tout : même les outils
internes du système (les choses
comme pm, dumpsys, etc.) sont difficiles à
utiliser entre autres faute de documentation. J'ai commencé il y a un
certain temps à écrire une
page où je rassemble les différentes choses que je réussis à
glaner par ci par là, mais ça reste extrêmement fragmentaire. Un
exemple emblématique pourrait être le format APK qui sert
à distribuer les applications Android : il est extrêmement difficile
d'extraire un APK, de le modifier, et de le remettre en
place (par exemple pour lui retirer de force une permission qu'il
aurait demandée), et le fait que les APK soient signés
n'est que le début des difficultés !
Un exemple concret. Pour ne pas perdre mes données en passant de
mon Nexus 4 à mon nouveau Nexus 5, je me suis dit que j'allais
recopier la partition de données utilisateur (/data) de
l'un vers l'autre (après avoir installé exactement la même version de
CyanogenMod sur les deux, bien sûr, pour minimiser les emmerdes, et
quitte à effacer quelques données particulières au téléphone, comme la
clé android_id de la table secure dans la
base de
données /data/data/com.android.providers.settings/databases/settings.db).
Au final, ça a marché. Mais non sans mal. Par exemple, parce que le
format .img des images acceptées par la
commande fastboot du bootloader Android de Google, elle
est certes documentée, mais dans
un header
obscur qu'il faut aller chercher soi-même au milieu du fatras des
sources d'Android. Et il n'y a bien sûr aucun outil standard pour
convertir agréablement vers ce format. Après ça, je n'avais encore,
bien sûr, aucune idée de ce qu'il faut et ne faut pas recopier
dans /data d'un téléphone vers l'autre (ce qui fait
partie, disons, de ma personnalisation du téléphone et ce qui fait
partie de la configuration du matériel précis). La réponse de Google
à ce problème est quelque chose comme : confiez-nous vos données (par
exemple, tous vos contacts), nous vous permettrons de les sychroniser
sur tous vos téléphones — seulement, moi, je n'ai pas envie de confier
ces données à Google (par exemple parce que je ne suis pas certain que
tous mes amis seraient d'accord pour que leur adresse soit communiquée
par moi à Google). Mais je digresse.
Il existe bien des bidouilleurs Android. Un de leurs points de
rassemblement est le forum en
ligne XDA-Developers
(par
exemple, ce
document est encore ce que j'ai trouvé de mieux comme
documentation sur comment compiler Android). Mais, outre que ce forum
est merdique pour des simples raisons de forme (outre l'abus de Comic
Sans, il est surtout impossible d'y retrouver quoi que ce soit), cette
sous-communauté souffre de beaucoup des mêmes défauts que la
communauté Android en général : si vous exposez un problème, on va
vous dire d'installer telle ou telle application dont on ne vous
montrera pas les sources ; et des versions complètes d'Android s'y
échangent par des liens douteux vers des sites d'hébergement de
binaires louches, sans qu'on sache si les sources sont disponibles
quelque part. Et je pense que c'est un problème assez profond, ou au
moins le symptôme d'un problème assez profond, que les développeurs
Android chez Google ne parlent essentiellement pas à cette
communauté-là.
Tout ceci me décourage beaucoup. J'aimerais passer mes téléphones
à autre chose qu'Android, mais il n'y a rien d'autre. Ce n'est même
pas la peine de parler de Windows mobile ou d'iOS, ce
dernier est auss ouvert que la Corée du Nord, alors évidemment,
Android, en comparaison, paraît vraiment paradisiaque. J'aimerais
énormément
que Firefox OS
ait du succès, parce que Mozilla m'a l'air d'être un agent très
bénéfique en direction de l'ouverture du Web et il pourrait jouer un
rôle semblable sur le marché des mobiles (et par ailleurs j'aime bien
l'idée d'unifier les applications mobile et les pages Web, surtout
quand la plupart des applications mobiles sont, de
fait des versions merdiques de sites
Web), mais il faut dire que trouver un mobile sous
Firefox OS, ce n'est pas évident (je me suis acheté un
Geeksphone Revolution, mais c'est une merde pour plein de raisons que
je n'ai pas le temps d'expliquer ici, et en tout cas il n'est pas du
tout ouvert) ; les téléphones développeur Firefox OS ont
l'air tous épuisés. Quant
à Tizen, il n'a pas
l'air promis à un grand succès, et pour commencer le SDK
est propriétaire (et Mer et Sailfish ont l'air encore plus
confidentiels). Peut-être qu'Ubuntu Touch apportera une embellie,
mais je n'y crois pas des masses non plus. En attendant, je suis à
peu près coincé sous Android.
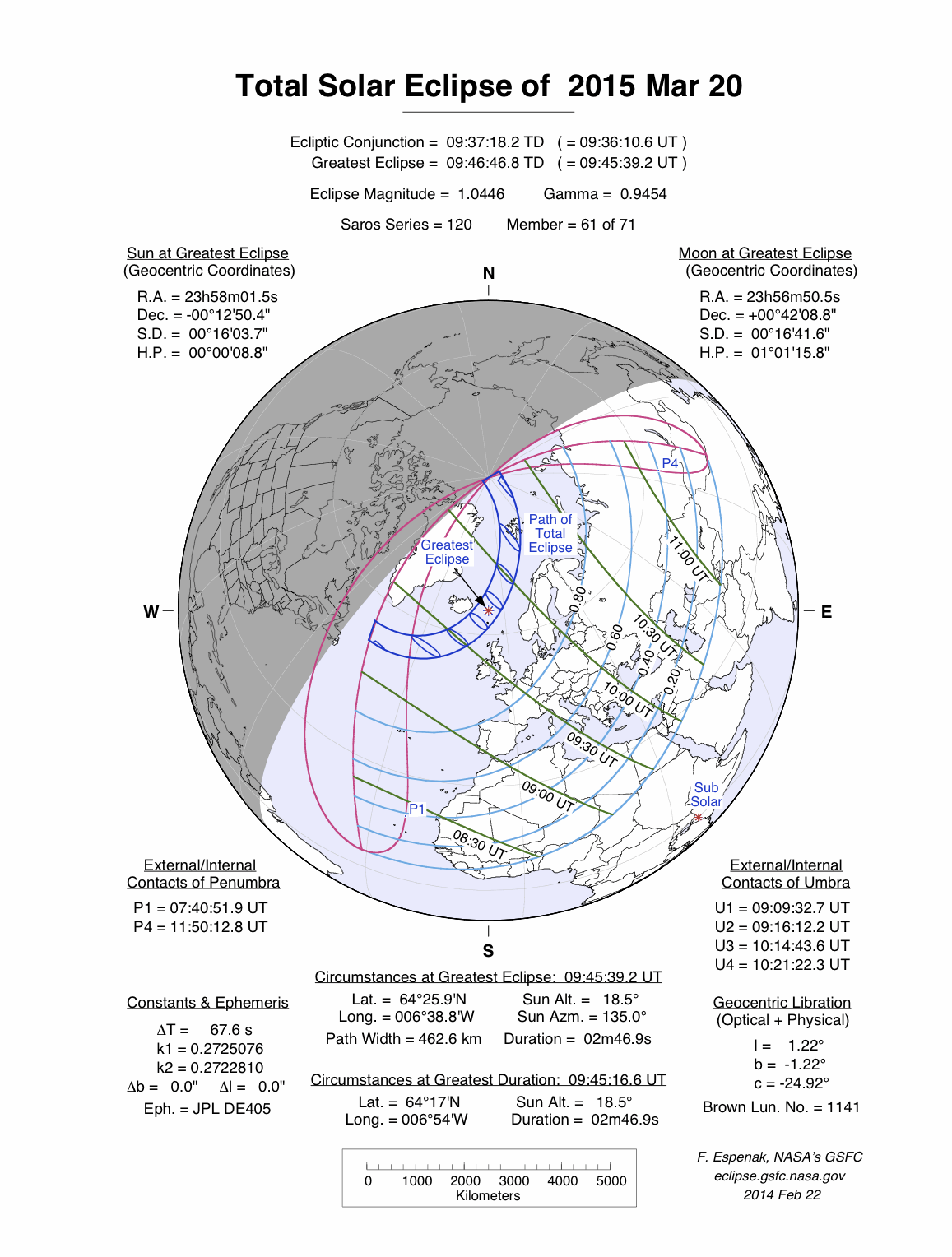
![[Diagramme de l'éclipse du 2015-03-20]](../images/SE2015Mar20T.png "Que signifient toutes ces annotations ?")
![[Affiche d'instructions]](../images/safety-instructions.jpg "Rien ne vous choque ?")
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}