Méta : Encore une entrée qui à force de trop rallonger s'est transformée en foutoir, et dont j'ai fini par avoir marre, alors, comme mentionné dans l'entrée précédente, je la publie telle quelle, après une relecture extrêmement minimale, même si je n'en suis pas content et qu'elle est assez inachevée, mais c'est ça ou bien la laisser moisir dans mes cartons indéfiniment.
Je commence par un point terminologique sur le sens des
mots emoji
et émoticône
et la différence entre les
deux :
-
Les emojis (ou
les emoji
, je ne sais jamais bien si c'est une bonne idée d'attacher un pluriel français en -s à un mot d'une langue qui n'a pas de pluriel ; du japonais
, signifiant quelque chose comme絵 文字 caractère-dessin
), sont des caractères pictographiques ou idéographiques prévus pour être insérés dans, mélangés à, ou utilisés comme, du texte écrit ordinaire.L'histoire des emoji est un peu confuse parce qu'ils ont été inventés plusieurs fois, ou disons que cela dépend de ce qu'on appelle exactement un emoji (en étant suffisamment large, on peut dire que les hiéroglyphes égyptiens sont des emojis quand ils ne servent pas à représenter des sons), mais on les attribue généralement à l'opérateur de télécommunications japonais NTT Docomo, qui a introduit en 1995 un symbole de cœur dans son pager, puis un jeu de 176 emojis (en format 12×12 pixels) dans sa plate-forme Internet mobile en 1999.
Dans Unicode spécifiquement (voir cette entrée récente pour quelques généralités sur Unicode), il s'agit de glyphes bien précis pouvant être représentés par un caractère unique ou par des combinaisons bien précises de caractères définies par le standard. Par exemple, côté caractères uniques,
U+1F600 GRINNING FACEreprésente un emoji de smiley souriant largement ‘😀’, tandis queU+1F4A9 PILE OF POOreprésente un emoji de tas de merde ‘💩’ ; pour ce qui est des combinaisons de caractères, par exempleU+1F1EA REGIONAL INDICATOR SYMBOL LETTER E+U+1F1FA REGIONAL INDICATOR SYMBOL LETTER Ureprésente un emoji de drapeau européen ‘🇪🇺’, tandis que la combinaison assez complexeU+1F3F3 WAVING WHITE FLAG+U+FE0F VARIATION SELECTOR-16+U+200D ZERO WIDTH JOINER+U+1F308 RAINBOWreprésente un emoji de drapeau arc-en-ciel ‘🏳️🌈’ (c'est mignon : on fabrique un drapeau arc-en-ciel en « combinant » un drapeau blanc avec un arc-en-ciel…) ; mais on considère dans tous les cas qu'il s'agit d'un emoji.Une des particularités de ces caractères est qu'ils ont généralement des couleurs spécifiques. Ce n'est pas imposé par le standard, mais c'est ce qu'on observe typiquement quand il s'agit d'afficher sur un écran couleur. (Les polices informatiques traditionnelles n'étant pas prévues pour stocker des informations de couleur, ça a d'ailleurs causé toutes sortes de difficultés techniques pas complètement — ou pas très proprement — résolues d'obtenir cet effet.)
Mais comme je le disais dans l'entrée liée ci-dessus, certains caractères ont une double nature, emoji ou non-emoji, ou plus exactement, peuvent coder un glyphe emoji (donc typiquement en couleur) ou un glyphe non-emoji selon qu'on les fait suivre du
sélecteur de variation
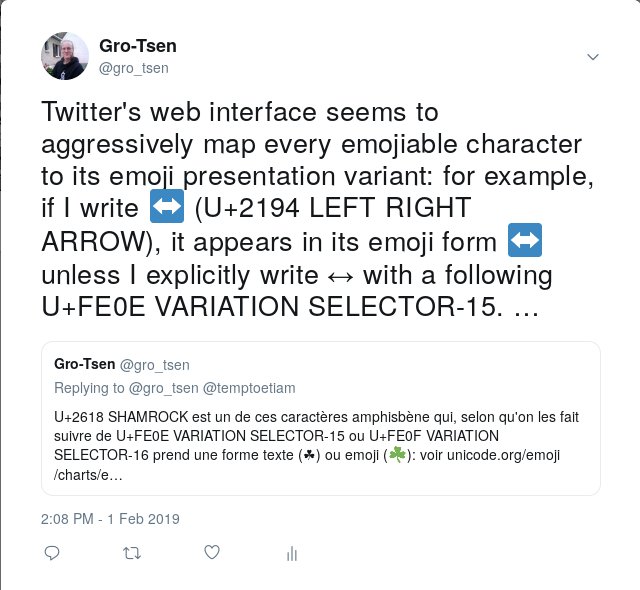
numéro 15 ou 16 : je donnais l'exemple du caractèreU+2620 SKULL AND CROSSBONESreprésentant une tête de mort au-dessus de tibias/fémurs croisés, qui peut servir à coder l'emoji ‘☠️’ quand il est suivi deU+FE0F VARIATION SELECTOR-16, ou bien le caractère explicitement non-emoji ‘☠︎’ quand il est suivi deU+FE0E VARIATION SELECTOR-15.La distinction devient là un peu byzantine (en quoi est-ce que ‘☠︎’ n'est pas un caractère idéographique ? si ce n'est pas une question de couleur, qu'est-ce que ça veut dire au juste, d'être un emoji ?), mais au moins, pour ce qui est d'Unicode, il y a une définition précise. En pratique, c'est assez clair, quand même : la forme emoji est un petit dessin qui vient décorer un texte pas très sérieux ou peut-être signaler une émotion tandis que la forme non-emoji est plutôt un symbole qui aurait sa place dans un texte sérieux. Je me suis d'ailleurs plaint que l'interface Web de Twitter « emojifiait » abusivement, et que si je veux écrire une bijection A↔B dans un texte mathématique, ça m'agace qu'elle apparaisse sous forme d'emoji ‘↔️’ [si vous ne voyez pas d'emoji ici, cliquez sur cette image pour avoir une idée] si je ne prends pas le soin explicite de mettre un
U+FE0E VARIATION SELECTOR-15après. -
Les émoticônes (
emoticons
?emotica
? quidlibet…) sont des façons de représenter des émotions dans du texte, notamment/typiquement des sourires plus ou moins heureux, auquel cas on peut parler desmileys
, terme parfois considéré comme interchangeable avecémoticône
(bien qu'il existe des émoticônes qui ne sont pas des smileys et peut-être réciproquement).Cela peut être fait par l'usage de caractères spécifiquement dédiés à cet effet, comme ‘☻’ (
U+263B BLACK SMILING FACE), qui peuvent être ou ne pas être des emojis (cf. ci-dessous), ou bien en détournant des caractères ayant en principe un usage différent, par exemple les caractères de ponctuation servant à construire le smiley ‘:-)’ (U+003A COLON+U+002D HYPHEN-MINUS+U+0029 RIGHT PARENTHESIS).Comme l'histoire des emojis, celle des émoticônes est confuse et on peut trouver toutes sortes de précurseurs selon ce qu'on qualifie exactement d'émoticône. Les smileys qui détournent les caractères ASCII (on parle donc de smileys en ASCII-art) comme le dernier exemple que je viens de donner, sont généralement rattachés à un message précis posté le dans un forum informatique de CMU proposant l'usage de ‘
:-)’ et ‘:-(’ pour marquer les blagues et les choses qui n'en sont pas. Le jeu de caractères CP437 de l'IBM-PC (qui doit dater de 1981) incluait en toute première position des caractères ‘☺︎’ et ‘☻’ (un visage souriant en vidéo normale et inverse, donc), qui pouvaient servir comme dessins (je m'en suis beaucoup servi pour représenter le héros dans des petits jeux que je programmais en BASIC ou Pascal dans les années 1980), mais n'étaient pas facile à utiliser dans du texte puisqu'ils étaient classés comme caractères de contrôle : on peut débattre s'il s'agissait d'une émoticône ou pas, ou d'un emoji ou pas.En tout cas, les termes
emoji
etémoticône
sont sans rapport, et leur similarité est accidentelle (au moins formellement : il est difficile exclure complètement, par exemple, que la similarité avec le mot anglaisemotion
ait en partie inspiré la composition du mot japonais絵文字
, ou que la confusion ait joué dans la popularité du mot en-dehors du japon). -
Même s'il y a un certain flou dans la définition des deux termes, les propriétés d'être un emoji et d'être une émoticône sont indépendantes. Par exemple, ‘🌍’ (
U+1F30D EARTH GLOBE EUROPE-AFRICA) est indubitablement un emoji, mais ce n'est pas une émoticône puisqu'il ne s'agit pas de représenter une émotion de celui qui écrit. À l'inverse, ‘:-)’ est une émoticône mais n'est pas un emoji, en tout cas pas au sens formel d'Unicode (d'ailleurs, au sens formel d'Unicode, même ‘☻’ et ‘☺︎’ [ce dernier devrait apparaître comme la version noir et blanc inversée du précédent] ne sont pas des emojis, contrairement à ‘😀’).Ceci étant, je répète qu'il y a forcément une certaine dose de flou sur ce qui est ou n'est pas quoi. Par exemple, à l'heure de gloire des smileys en ASCII-art, certains s'amusaient à en composer de plus en plus complexes (comme le smiley
père Noël
‘*<:-{)#’), juste pour le plaisir de les dessiner et plus pour représenter une émotion : du coup, je ne les classerais ni dans les emojis ni dans les émoticônes, alors que ce sont quand même des smileys… bref, ce n'est pas très important.
Comme je l'ai écrit ci-dessus, l'histoire des emojis et des
émoticônes est confuse et se recoupe au moins partiellement. Si les
smileys en ASCII-art sont apparus vers le début des
années 1980, et si les japonais ont développé leur propre style de
smileys (kaomoji
, par exemple ‘{^_^}’) dans la seconde moitié des
années 1980, c'est surtout avec le développement des webforums dans
les années 1990–2000 que les émoticônes ont commencé à prendre le
chemin des emojis : remplaçant automatiquement (ainsi que certains
logiciels de mail) les séquences ASCII-art (comme
‘:-)’) par des dessins plus représentatifs, ils se
sont mis à multiplier les possibilités de smileys insérables depuis
une interface ad hoc et ont certainement beaucoup fait pour les
rendre populaires auprès des internautes. Je pense à des
dessins comme ça (ou
plus généralement ce que renvoie
une recherche
Google Images de phpbb smileys
), qui font maintenant très
datés début des années 2000
mais qu'on continue à trouver çà et
là sur le Web (y compris sur ce blog, cf. ci-dessous).
Rappelons à toutes fins utiles que si Unicode définit des caractères et séquences de caractères censés représenter des emojis, au final, les dessins réellement affichés dépendent des polices installées et typiquement du concepteur du système d'exploitation ou smartphone (ou autre gadget) utilisé pour lire le texte ; certains emojis sont sujets à des différences de représentation (et donc d'interprétation) assez importantes : il ne faut pas compter sur le fait que la personne à qui vous envoyez un message contenant des emojis verra forcément la même chose que vous (outre les problèmes de différences de dessins, il peut y avoir celui des manques, puisque tout le monde n'a pas forcément la panoplie complète).
⭐️
Maintenant, on peut se poser un certain nombre de questions :
- Est-ce que tout ça est bien utile ? À quoi est-ce que ça sert exactement ?
- Et plus spécifiquement : est-ce qu'Unicode a eu raison de céder et de commencer à encoder les emojis dans le Standard, au risque de glisser sur la pente d'une ménagerie qui n'en finit plus de dessins en tous genres ?
Sur le premier point, mon avis est qu'indubitablement, oui, au moins les émoticônes ont un intérêt : elles facilitent réellement la communication et évitent notamment des malentendus de ton ou de degré en explicitant par écrit des choses qui, à l'oral, passeraient dans l'intonation de la voix, la gestuelle ou le visage. Elles ne sont évidemment pas indispensables ; mais la ponctuation n'est pas non plus indispensable : et comme la ponctuation, elles servent à donner une sorte de méta-information périphérique à l'interprétation d'un énoncé, en l'occurrence une sorte de contexte émotionnel. Contexte et méta-informations qu'on pourrait bien sûr indiquer explicitement par des mots (comme on pourrait se passer du point d'interrogation et d'exclamation par des adverbes et des tournures de phrase bien choisis) mais au prix de beaucoup plus de lourdeur dans l'expression. Quant à l'argument selon lequel on se passait bien de smileys avant les ordinateurs (ou qu'on n'imagine pas Victor Hugo dessiner une petite tête souriante à la fin d'une phrase pour la rendre plus légère), il fait semblant d'ignorer le fait que la communication écrite ne s'est pas seulement développée, elle s'est aussi diversifiée, et qu'il est normal que des nouveaux usages entraînent des nouveaux besoins. (Pour reprendre mon analogie entre émoticônes et ponctuation, je ne serais d'ailleurs pas surpris que la nécessité ressentie à l'introduction de la ponctuation ait été semblablement liée à une diversification et démocratisation des usages de l'écrit.)
Bref, je ne comprends pas plus ceux qui semblent s'interdire l'usage du moindre smiley que ceux qui s'interdiraient le point d'interrogation ou le point d'exclamation : tout dépend du contexte, bien sûr, peut-être que dans un texte de loi ou dans un contrat il est mal vu de faire usage de points d'interrogation et d'exclamation et je comprends qu'on soit semblablement réticent à l'usage de smileys dans des contextes un peu formels (où de toute façon on n'est pas censé s'interroger sur l'émotion de la personne qui écrit), mais je ne comprends pas un refus catégorique de leur emploi en général.
Évidemment, a contrario, il y a ceux qui en abusent, et qui
trouvent utile d'ajouter douze smileys ‘😂’
(U+1F602 FACE WITH TEARS OF JOY)
et/ou ‘🤣’ (U+1F923 ROLLING ON THE
FLOOR LAUGHING), qui sont sans doute les plus abusés, à la fin
de la moindre remarque drôle / moqueuse / sarcastique. Mais il y a
aussi des gens qui abusent des points d'interrogation et d'exclamation
(five exclamation marks, the sure sign of an insane
mind
), ce n'est pas une raison pour ne pas s'en servir.
Si vous voulez un bon exemple d'utilisation modérée et raisonnable
des smileys, prenez exemple sur moi. ![]()
Le dernier paragraphe n'était pas sérieux, bien sûr, mais constitue
un exemple de cas où je considère vraiment utile de mettre un
smiley — par opposition au fait de ne rien mettre du tout (il y aura
toujours quelqu'un pour me prendre au sérieux, aussi évidente que soit
la blague, et parfois je veux devancer les malentendus) ou au fait de
signaler l'humour par quelque chose de plus explicite (comme le
dernier paragraphe n'était pas sérieux
…). Et je ne pense vraiment
pas qu'on puisse m'accuser de faire un usage immodéré des smileys sur
ce blog : un dénombrement rapide suggère que j'en ai utilisé 336 sur
2596 entrées de blog (ou 16 ans).
⭐️

 Maybe you can now see a little
icon appear somehow associated with my Web pages in your Web browser
(
Maybe you can now see a little
icon appear somehow associated with my Web pages in your Web browser
({kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}